基於Obsidian的西夏文錄文、IPA、Glossing Abbreviations、翻譯
2024年3月26日
轉載自基於Obsidian的西夏文錄文、IPA、Glossing Abbreviations、翻譯。
前言
筆者在跟隨馬洲洋老師學習西夏文的時候,曾經採用的是傳統的Word輸入法(現在不少中文學界的學者也是在Word當中插入表格解決問題),但時常受困於Word的不專業、不便利。因為Word的Fallback Font機制混亂的緣故——不能精準的針對不同語言、書寫系統,在西夏文、英文、中文混排的時候,如果一些操作系統介面不支持西夏文字體,那麼西夏文就不能正常顯示,就剩下一個空白的方框。Fallback Font存在的意義就在於:讓任何文字都得到正常的顯示,不需要依賴一個一個字手動操作,去為文本中不同語言的文字分別指定字體,哪怕是很小眾的需求都應該被尊重。其實不只是西夏文這麼小眾需求面對窘境,在帶音調的字母如拼音、中文與日文混排、英文與希臘文混排也會出現排版混亂問題。
因為筆者是一名歷史學的學生,並非語言學專業,所以學習Latex的成本略微高了一些(當然以後要學啊!),但是筆者想要在西夏文輸入排版方面變得更方便,變得更加專業。因此對於筆者來說,使用Obsidian輸入西夏文是學習成本最低、入手最方便快捷的處理方式。雖然有些成形的習慣很難改變,如依賴Word文檔、依賴景永時字體⋯⋯但是需要有這麼一個選擇告訴我們——文檔編輯可以在更輕鬆、更方便的基礎之上——變得更加專業。
寫這篇文章的目的是:用最淺顯的語言,讓計算機小白都能讀明白、會用文中的各個功能,把程序跑起來,寫一些最基本的語句。
本文材料來源
1.思路是旗魚師傅的博客文章:《文本编辑器西夏文字体配置解决方案》。
2.具體依賴的外掛程序是Github中Mijyuoon上傳的《Obsidian Interlinear Glosses》,及其相關語法學習。
3.語法縮寫的相關術語來自維基百科,簡單直接。
4.功德無量的Jerry老師所建立的《古今文字集成》網站。
需要預裝的程序
1.本文所講的核心軟件:Obsidian,官網下載。
2.西夏文的相關輸入法,Jerry老師的網站上已經寫的很詳細了(同樣,Mac OS還是比Windows系統更加麻煩,Mac的輸入法選擇面更窄:如筆者下載的「鼠鬚管」在解壓、最開始的操作過程中都有不穩定的情況,需要磨合。解壓問題很可能已經得到了解決,後續筆者與Jerry老師測試過,應該是當時文件的壓縮工具導致的)。
3.西夏文字體的安裝,同樣見Jerry老師的網站。筆者最推薦的是西夏文的Unicode字體Tangut N4694;其次需要下載景永時字體備用,因為從知網下載早年的《西夏學》《西夏研究》等期刊,會發現西夏文部分都是「漢字亂碼」,這是因為景永時的工作原理是用漢字佔位符替換對應的西夏文,因此這些漢字用景永時字體查看就可以;還有一種方法就是下載Jerry老師的西夏文字體轉換工具。
(為了跑最後旗魚老師的程序——雖然終端機、文件資源管理器就可以代替,但還是可以選擇性安裝:VS code,搭建好Python環境、裝入requests模塊,值得注意的是Mac OS可能會比Windows系統的電腦稍微麻煩一些。如筆者通過Homebrew安裝的Python環境,在終端機裡一定要使用諸如「Python3」、「pip3」的指令去安裝requests,一定要加版本!要不然終端機識別不出來「Python」、「pip」。re是Python內置的正則表達式庫、一個包管理器,從Homebrew途徑安裝的Python不需要單獨安裝pip。)
進入Obsidian介面
使用Obsidian的第一步是設置字體,路徑為:設置-外觀-文字字型,對於筆者來說:Times New Roman、Tangut N4694、Sim Sun(宋體,Simplified Sung)就可以滿足西夏文錄文、發音構擬、語法標註、翻譯的基本功能。需要注意此處的文字字型優先級,要按照筆者的順序來:因為SimSun、Tangut N4694均含有拉丁字母的字型。Obsidian會按序使用列表中字體來展示文檔的內容。因此如果Times New Roman的順序排在Tangut N4694、SimSun之後的話,在顯示英文內容時,會使用後二者中第二優先的Tangut N4694來渲染。如果希望使用Times New Roman或者其它英文字體展示英文內容,就要把英文字體的優先級提高到漢字字體之前。
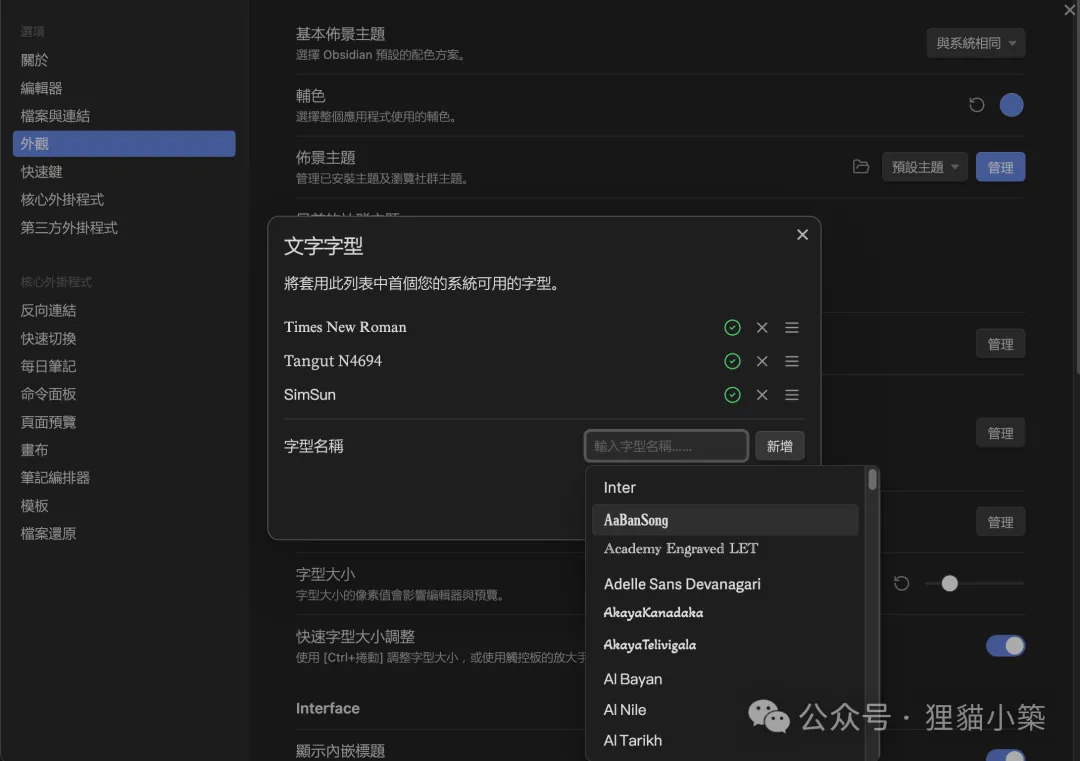
第二步是安裝第三方外掛程序“Interlinear Glossing”,首先依次點擊:設置-第三方外掛程式-受限模式,關閉受限模式之後才正常安裝。接下來點擊:社群外掛程式旁的“瀏覽”,搜索程式“Interlinear Glossing”,下載、安裝。最後點擊:已安裝外掛程式旁的打開按鈕,即可正常工作。
由於直接使用“Interlinear Glossing”會導致使用“\gla”行命令的西夏文錄文是斜體,斜體對於英文、德文等西文字母而言是好看的,但是就西夏文顯示而言,會變得有些不太舒服——字體的斜體(Italic)字形一般需要專門設計,當字體中不含有這種字形時,否則會使用算法渲染出的偽斜體字形。英文字體中一般同時含有直立和斜體的字形,因此可以用字體的名字同時指定多種字形。而東亞文字的字體中一般只有直立字形,因此需要軟件支持才能對字形進行細粒度的安排(例如直立字形使用宋體,斜體字形使用楷體)。因此在沒有這種意識的軟件中,斜體字形會使用算法生成的“不好看的”偽斜體。
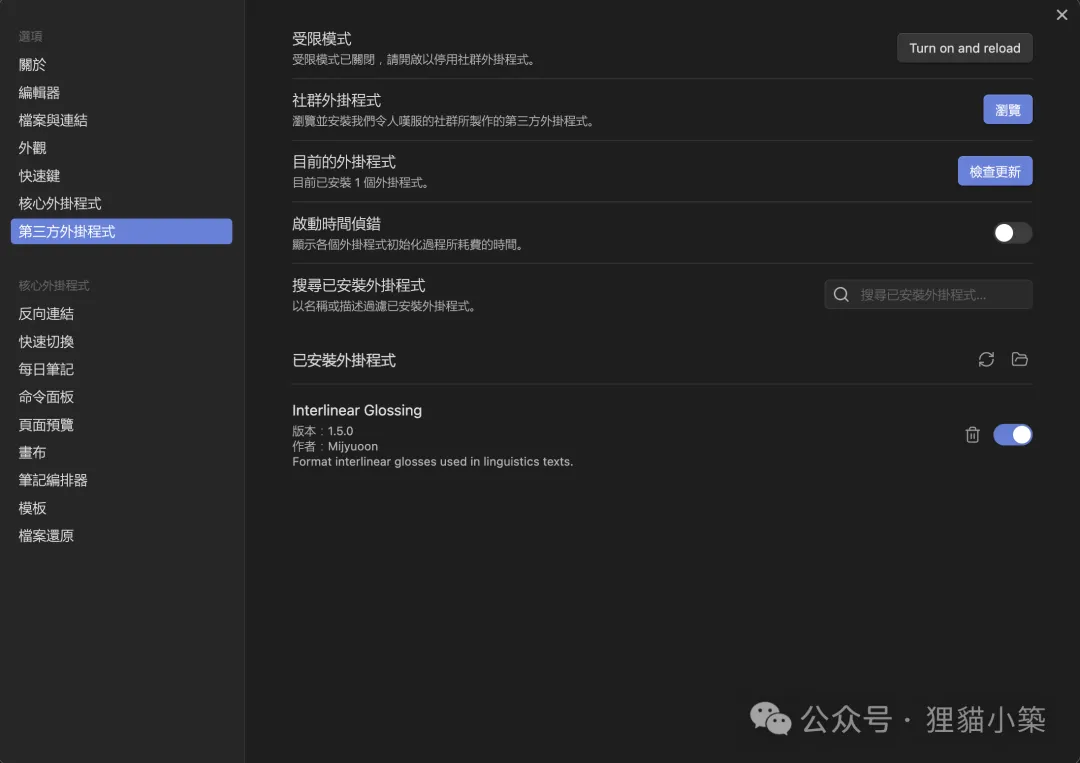
因此可以選擇修改一行代碼。點擊:設置-外觀- CSS片段,在Obsidian的系統文件夾“vault/.obsidian/snippets”中創建一個文件(關於怎麼找到這個文件夾:Windows直接使用“文件資源管理器”導航到指定目錄,在其中創建新的文本文件,並用“記事本”進行編輯;macOS在訪達中搜索導航到指定目錄,在文件夾裡創造一個“.css”文件,可借助本身的終端機或下載的VS Code進行下文所說的代碼複製),筆者將文件命名為“normal-tangut”.css
在其中輸入一行代碼:
.ling-gloss-level-a { font-style:normal; }
電腦右上角是“閱讀”、“編輯”模式的切換鍵,點擊符號即可切換,如圖:

外掛程序使用方式
接下來的部分是外掛程序的使用方式,大佬們可以直接移步本文最前面列出的Github鏈接,裡面有Mijyuoon製作的所有功能,筆者在這裡僅僅介紹一下西夏文文本編輯中所需要的基本語句輸入方法。
首先把鍵盤調成西文輸入模式,輸入成如圖形式:

這些符號和字母代表這是一個代碼,在一對反撇號中間的行裡,可以輸入代碼所需要的語句。
原始錄文可以使用“反斜槓符號ex空一格”的命令來實現,在程序中空格都是有意義的,不能隨意省略!如圖:

第一行使用“反斜槓符號a空一格”的命令實現,西夏文Unicode字符之間也需要空格,如圖:

值得注意的是,如果你覺得一行代碼太長,可以通過縮進來分成多行書寫,不會造成任何顯示方面的影響,如圖:

同樣,代碼和代碼之間的空行也不影響顯示,如在gla和glb之間不空行、空一行、空兩行⋯⋯都不影響最終各式的顯示。
第二行使用“反斜槓符號b空一格”的命令實現,同樣IPA之間也需要空格,如圖:

第三行使用“反斜槓符號c空一格”的命令實現,同樣含義、語法縮寫等之間也需要空格,且如果要標記語法縮寫的話,需要加入符號[]或-
伽旃延在這裡是人名,做主語;接受是謂語動詞,如圖:

第四行使用“反斜槓符號ft空一格”的命令實現,添加整句話的翻譯,如圖:

如果你想給你的錄文編號,可以使用“反斜槓符號num空一格”的命令實現,如圖:

如果你想告訴大家這是西夏文,可以使用“反斜槓符號lbl空一格”的命令實現,如圖:

如果你想告訴大家這句話的出處,寫個註釋,可以使用“反斜槓符號src空一格”的命令實現,如圖:

完成上述步驟之後,從編輯模式切換到閱讀模式,你將會看到:

之所以推薦Obsidian,是因為筆者使用Word不太順利,忘記切換字體,一不小心就會顯示不出來對應的字符,如果把這樣的文檔發給別人,將會對對方造成困擾。如筆者給馬洲洋老師交作業,一不留神西夏文字符就顯示不出來了,即thwu後面的空白方框:

匯出一個Obsidian文檔,點擊頁面右上角的省略符號-匯出PDF,如圖:
旗魚師傅製作了一段Python代碼,只需要輸入西夏文Unicode(由於四角號碼的輸入、景永時字體的輸入需要改變很多程序中的語句,這個程序只支持Unicode查詢)就可以自動獲得龔煌城的擬音、李範文先生在《簡明夏漢字典》之中的釋義。我們期待旗魚師傅能夠在未來加入韓小忙先生的詞典、三宅英雄、克恰諾夫的擬音。
代碼如下:
建議直接複製博客內容!微信排版混亂
```python
import requests
import re
def check(s):
url = 'http://ccamc.org/tangut.php?n4694=' + s
r = requests.get(url)
pattern_om = re.compile('
龔煌城:(.*?)')
om = re.findall(pattern_om, r.text)
om = om[0]
pattern_imi = re.compile('2012版《簡明夏漢字典》釋義
(.*?)
')
imi = re.findall(pattern_imi, r.text)
imi = imi[0]
try:
pattern_tone = re.compile('(.*?)\\.')
tone = re.findall(pattern_tone, r.text)
tone = tone[0]
except Exception:
tone = ''
return om, imi, tone
if __name__ == '__main__':
while True:
raw = str(input())
om_list = []
for i in raw:
try:
result = check(i)
om_list.append(result[0]+result[2])
print('{0}:音:{1},义:{2}'.format(i, result[0]+result[2], result[1]))
except Exception:
print(i)
continue
print(' '.join(om_list))
````
筆者在VS Code當中的Python環境中運行,輸入了四個西夏文Unicode,輸出結果如圖:
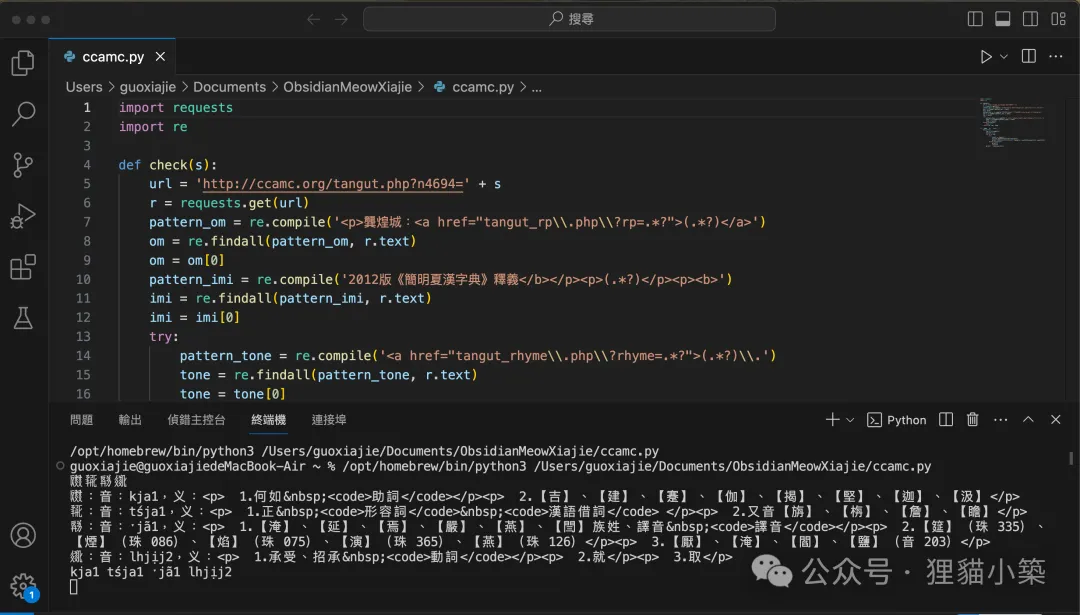
非常好用!
最後,讓我們一起說:謝謝旗魚!謝謝Mijyuoon!謝謝Jerry!謝謝IT俠們!MTGA!
感謝馬洲洋老師的審閱!
夾帶一個私貨提醒:
在2005與2006,有兩版《夏俄漢英詞典》。首先此書的公開數字化幾乎沒有,很難找到。美國國會圖書館藏05版(也即Jerry老師錄入版),而俄羅斯有06版,在VK上可找到(張恩輔學長貢獻版)。舊版5803個字頭,新版5683個字頭,進行增補,且多了術語表,出版社也不一樣。這導致筆者之前詢問洲洋老師某詞,反查時使用06版壓根兒對不上05的序號,以為Jerry老師錄錯了,後來兩邊一合計,才打通雙方的信息壁壘。所以目前使用Jerry老師的錄入,一定要查05版的序號!